Qualtrics & egor: Setting up and analysing an ego-centered network survey with Qualtrics and egor
Joy Losee, Till Krenz
Source:vignettes/qualtrics.Rmd
qualtrics.RmdAs researchers increasingly opt for online data collection for social
network projects, they may find programming the survey and downloading
the data from that survey challenging. So, we’ve developed the following
tutorial to make the process between data collection with Qualtrics and
data analysis with egor more seamless. If you have any
questions or suggestions please open an issue on
github or send an
email.
While details will differ the same general logic described here can be applied to other survey platforms, as RedCap, ScoSci Survey, etc.
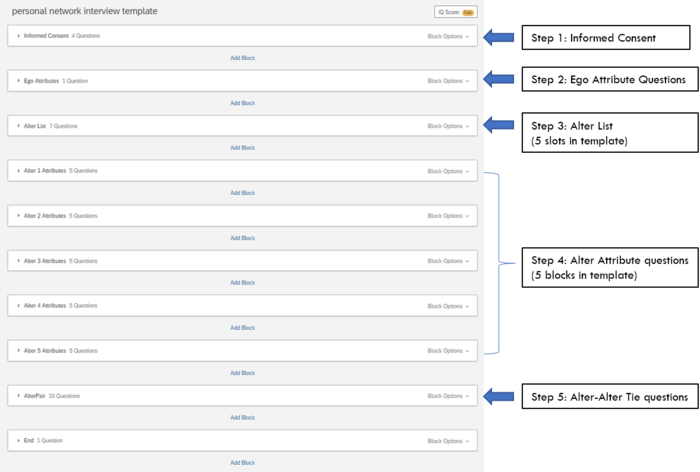
Structure of an ego-centered network survey
- Ego Attribute Section. Includes questions about the ego (e.g., demographics, personality inventory, etc.).
- Name Generator: Alter List. Participants will list their alters in this section. Alter names are then piped into the alter attribute and the alter-alter tie sections. The participants can be free in their choice of how many alters they want to name or they can be forced to fill out a specific number of alter names.
- Name Interpretator: Alter Attributes. This section of the survey is used to collect alter attributes (e.g. gender, age, etc.) and characteristics of the ego-alter relationship (e.g. contact frequency, emotional closeness, etc.).
- Alter-Alter Tie. In this section, participants generate information on the alter-alter ties. Alter-alter ties in ego-centered networks are usually collected as un-directed relations through a single question about the relationship between alter x and alter y.
Best practices
When conducting ego-centered network surveys some practices have proven to decrease drop-out rates and increase the quality of the collected data. Some of the items listed below apply to any kind of survey, while others are specific to ego-centered network data collection.
- Informed Consent
- Quality assurance: Ask participants to commit to providing their best answers.
- Thoroughly describe the data collection process. Make sure the participant is aware ahead of time how long the process could take and that there is no need to provide identifying information (unless you do plan to match alters across egos in your study or there is another reason to collect identifying). If identifying alter information is necessary, make sure to explain up front what you will do with that information. The template has slots for 5 alters, but can expand to any number of alters.
- Make sure that alter-alter questions are in the right order.
Create an Ego-Centered Network Survey
egor includes three template files for Qualtrics
surveys:
You can download the template that best fits your needs, import it into Qualtrics and build upon it, to create your own survey. To download right-click on the link above and select “Save link as…” (or similar).
Fixed-Choice
In this section we describe the logic behind the fixed-choice template, the following section describes the changes necessary to allow the participants free-choice of the number of named alters.
Ego Attributes: The ego attributes are usually collected before the name generator. You can do it after as well or both. These survey items are regular questions about the participants themselves, therefore we won’t further explain how to set this up.
Name Generator: This section can be customized, but there are two things to keep in mind. First, if you increase the number of requested alters (the template currently has slots for 5 alters), you will need to increase the number of alter attribute question blocks and alter-alter tie questions to match. Second, because this is the fixed choice template, this alter list requires that participants enter an alter for each slot to continue.
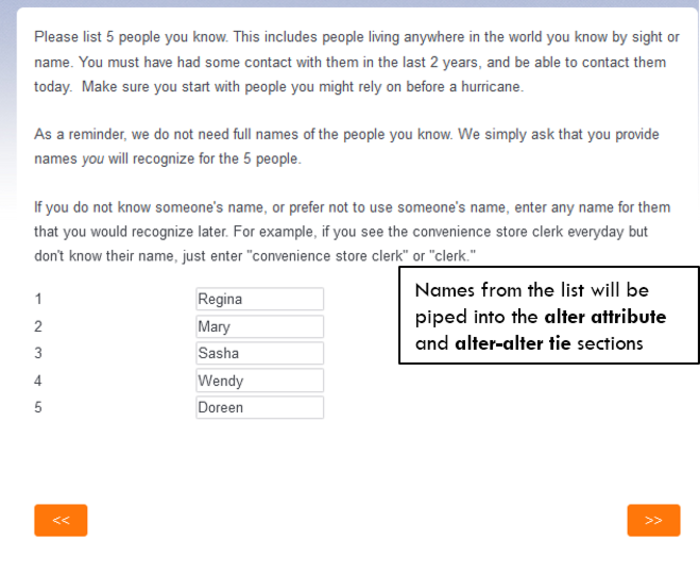
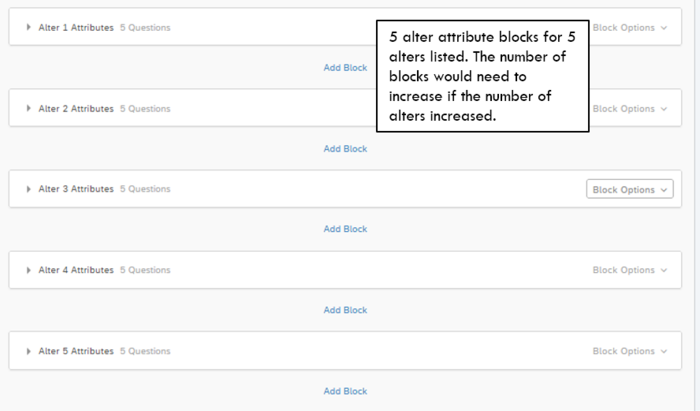
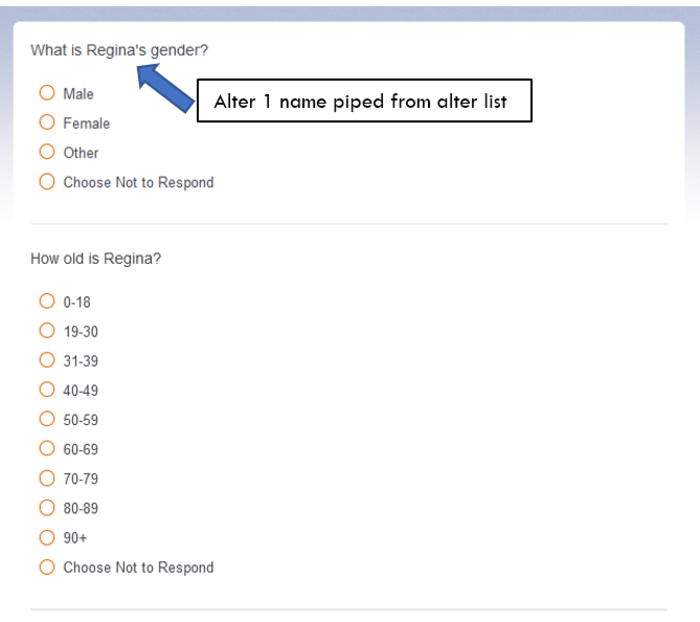
- Alter Interpretator: Alter Attributes. The template pipes the names provided in the alter list to the alter attribute questions. Click here for instructions on piping text in Qualtrics. Each set of alter attribute questions is separated into a question block labeled for that alter (e.g., Alter 1 Attributes, Alter 2 Attributes).
This section can be customized to change the number of questions about each alter and to change the wording and response style of each question. Like a standard survey—all other Qualtrics programming should work for the alter attribute questions. If you require more than 5 alters, you will need add as many blocks of alter attribute questions as alters listed (e.g., 10 alters listed would need 10 blocks of alter attribute questions). We recommend finalizing question wording and format in Block 1 of alter attribute questions and copying that block for as many alters as requested in the list. Then, in each block, adjust the code for the piped text so that it refers to the appropriate list slot (e.g., Block 2 of alter attribute questions should pipe the response to the second list slot from the alter list).
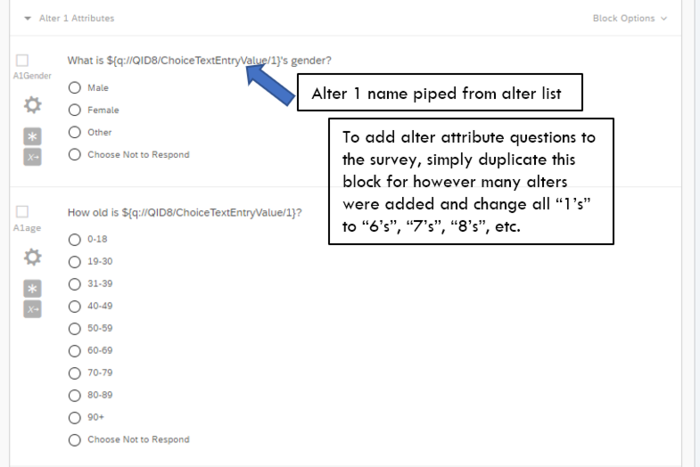
- Alter-Alter ties. The template has 10 alter-alter tie questions because the template asks for 5 alters. If you request more than 5 alters, you will need to add the corresponding number of questions to this section (e.g., requesting 30 alters means asking 30*(30-1)/2=435 alter-alter tie questions). These questions pipe in the names from the alter list using the same piped text code from the alter attribute section. Again, we recommend finalizing the question wording and style in the first alter-alter tie question and then copy-pasting the question as many times as needed adjusting only the piped text so that each question refers to the correct name from alter list. It is important to sort the order of alter-alter tie questions so that all ties from alter 1 (e.g., to alter 2, 3, 4, …) appear first, followed by all ties from alter 2 (e.g., to alter 3, 4, …) and so on. This process ensures that the alter attributes and alter-alter ties can be connected correctly when analyzing the data.
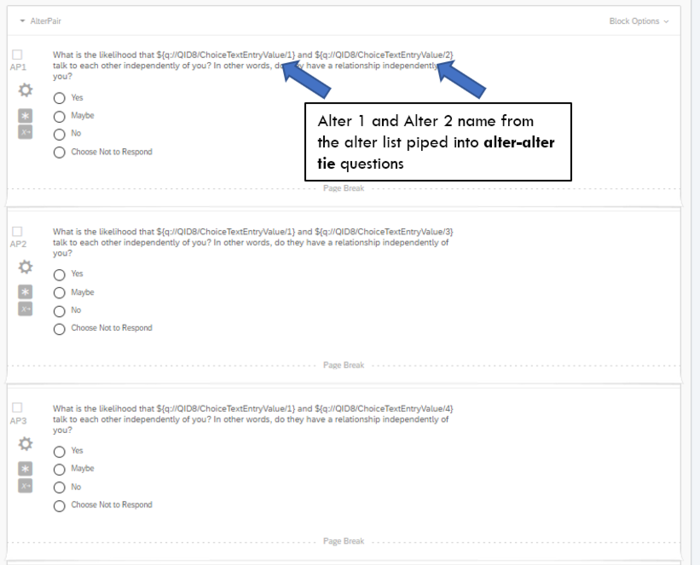
Free-Choice
Here we describe survey display logic changes necessary to allow the participants to chose themselves how many alters they name. While there will always be an upper limit of alters that can be named, by selecting a very high number for this, you can make sure that the participants can name all the alters they want. At the same time a high maximum number will also lead to a significant amount of additional work for the survey creation. Also with each additional alter named the participant will have to respond to more alter attribute and alter-alter questions.
Ego Attributes: No changes needed here.
Name Generator: To give participants the option to leave some names in the alter list blank, you will have to skip/delete the Custom Validations which check that the name fields contain names.
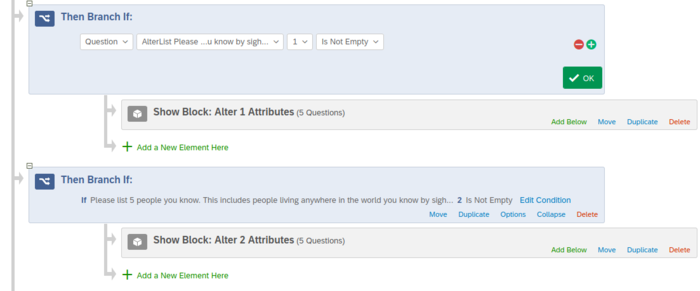
Alter Attributes: Because this is the free choice format, you will want to display only the same number alter attribute blocks as alters listed in the alter list. Thus, you will need to employ display logic using the Survey Flow tab in Qualtrics to define the conditions of when to display each alter attribute block.\
-
Alter-Alter Ties. Add Display logic to each alter-alter pair question that will hide questions if one of the alters to which the question refers is left blank. We recommend preparing and finalizing one alter-alter tie question including the Display Logic and then copy this question as many times as needed and adjust only the piped text and Display Logic for each alter-alter combination.
 Display Logic of an alter-alter question (free-choice only)
Display Logic of an alter-alter question (free-choice only)
Downloading the data and importing it with egor
- Download data from qualtrics in the CSV format. Click here for instructions on downloading data from Qualtrics
- Import data into R as an
egorobject with the code below.
qu_data <- read.csv(file = "filename.csv") # Replace file name with full data set name!
qu_data <- qu_data[3:nrow(qu_data),]
# Create egoID
qu_data$egoID <- 1:nrow(qu_data)
library(egor)
#> Loading required package: dplyr
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
#> Loading required package: tibble
e1 <- onefile_to_egor(egos = qu_data,
ID.vars = list(ego = "egoID"),
attr.start.col = "A1Gender", # Name of Variable with the first alter attribute
attr.end.col = "X5.5", # Name of variable with last alter attribute
max.alters = 5, # Number of maximum alters that were named by participants
aa.first.var = "AP1") # Name of first alter-alter variable
#> Sorting data by egoID:
#> Done.
#> Transforming alters data to long format:
#> Done.
#> Transforming wide dyad data to edgelist:
#> Done.
#> Note: Make sure to filter out alter-alter ties with invalid weight values.
#> Warning in onefile_to_egor(egos = qu_data, ID.vars = list(ego = "egoID"), : No
#> netsize values provided, make sure to filter out invalid alter entries.We need to filter out entries for alters left blank by respondents because the survey is structured so that each possible alter has an entry. This step is technically not necessary if you are certain that all respondents have named the maximum number of alters.
The logic behind this step is to first create a
logical vector that marks each alter as TRUE
(= exists) if the name cell for that alter is not empty and and as
FALSE if it is empty. Next this logical vector
is applied to the alter dataset in the egor object to
filter out all empty alter entries.
alter_filter <-
e1 %>%
as_tibble() %>%
arrange(.egoID) %>%
select(AlterList_1:AlterList_5) %>%
mutate(across(.fns = ~. != "")) %>%
as.data.frame() %>%
tidyr::pivot_longer(cols = everything()) %>%
pull(value)
#> Warning: There was 1 warning in `mutate()`.
#> ℹ In argument: `across(.fns = ~. != "")`.
#> Caused by warning:
#> ! Using `across()` without supplying `.cols` was deprecated in dplyr 1.1.0.
#> ℹ Please supply `.cols` instead.
e1 <-
e1 %>%
activate(alter) %>%
filter(alter_filter)Similar to the alter data the alter-alter ties contain rows that represent ties between alters that might not exist. These can be filtered out by excluding all rows/ alter-alter ties with an empty weight variable.
- Inspect
egorobject.
e1
#> # EGO data: 5 × 28
#> .egoID StartDate EndDate Status IPAddress Progress Duration..in.seconds.
#> * <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 1 2021-03-25 08:… 2021-0… Surve… "" 100 0
#> 2 2 2021-03-25 08:… 2021-0… Surve… "" 100 0
#> 3 3 2021-03-25 08:… 2021-0… Surve… "" 100 0
#> # ℹ 2 more rows
#> # ℹ 21 more variables: Finished <chr>, RecordedDate <chr>, ResponseId <chr>,
#> # RecipientLastName <chr>, RecipientFirstName <chr>, RecipientEmail <chr>,
#> # ExternalReference <chr>, LocationLatitude <chr>, LocationLongitude <chr>,
#> # DistributionChannel <chr>, UserLanguage <chr>, ZipCode <chr>,
#> # AlterList_1 <chr>, AlterList_2 <chr>, AlterList_3 <chr>, AlterList_4 <chr>,
#> # AlterList_5 <chr>, ID <chr>, Q_TotalDuration <chr>, gc <chr>, term <chr>
#> # ALTER data: 7 × 8
#> .altID .egoID A1Gender A1age A1relation A1Location_1 A1Location_2 A1Close
#> * <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 1 4 Choose Not t… Choo… Other ad "asd" Very c…
#> 2 2 4 Female 40-49 Spouse asd "asd" Not cl…
#> 3 1 5 Choose Not t… 31-39 School asd "" Somewh…
#> # ℹ 4 more rows
#> # AATIE data (active): 11 × 4
#> .egoID .srcID .tgtID weight
#> * <chr> <chr> <chr> <chr>
#> 1 4 1 2 Maybe
#> 2 5 1 2 Yes
#> 3 5 1 3 Maybe
#> 4 5 1 4 No
#> 5 5 1 5 Maybe
#> # ℹ 6 more rows
summary(e1)
#> 5 Egos/ Ego Networks
#> 7 Alters
#> Min. Netsize 0
#> Average Netsize 1.4
#> Max. Netsize 5
#> Average Density 1
#> Alter survey design:
#> Maximum nominations: 5- Start analysis. Take a look at the Using
Egor vignette to learn how to visualize and analyze ego-centered
network data with
egor.